What it looks like
One flow per worker. A small fleet of those. A thin tier of apps in front. Managed Postgres, Redis, and S3 behind — all in the same region.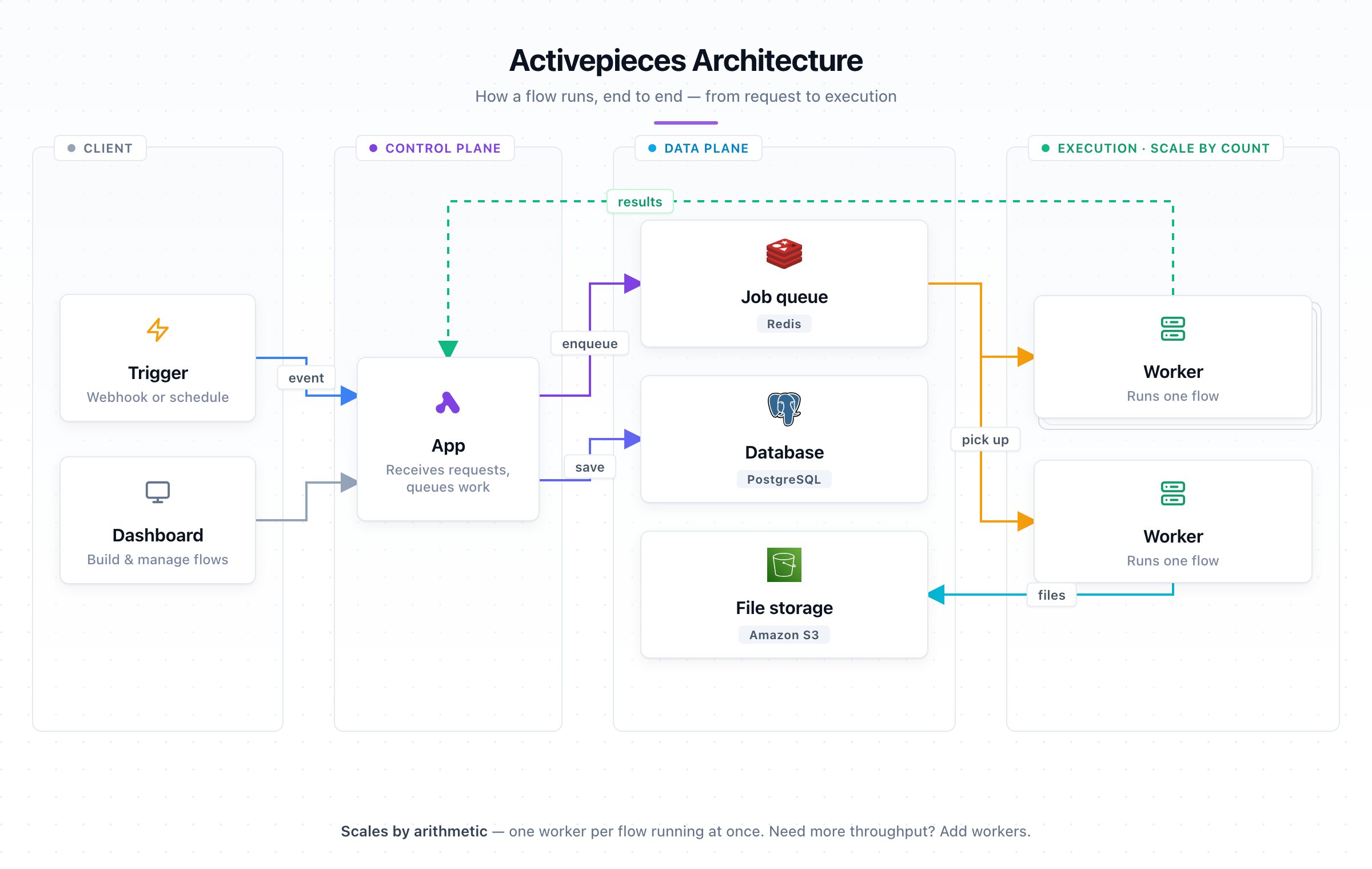
| Component | Size each | How many |
|---|---|---|
| Worker | 0.5 vCPU / 1 GB, concurrency 1 | one per concurrent flow |
| App | 1 vCPU / 1 GB | one per ten workers |
| Postgres | 2 vCPU / 4 GB, managed | one, grows with the fleet |
| Redis | 1 vCPU / 1 GB, managed | one |
| Object storage (S3) | same region, signed URLs on | required |
Recommended config
Copy this — it’s the exact configuration the benchmark below was measured on:Sizing
A concurrency-1 worker is busy for a flow’s whole duration (up to 10 min), so size by concurrent flows, not trigger rate: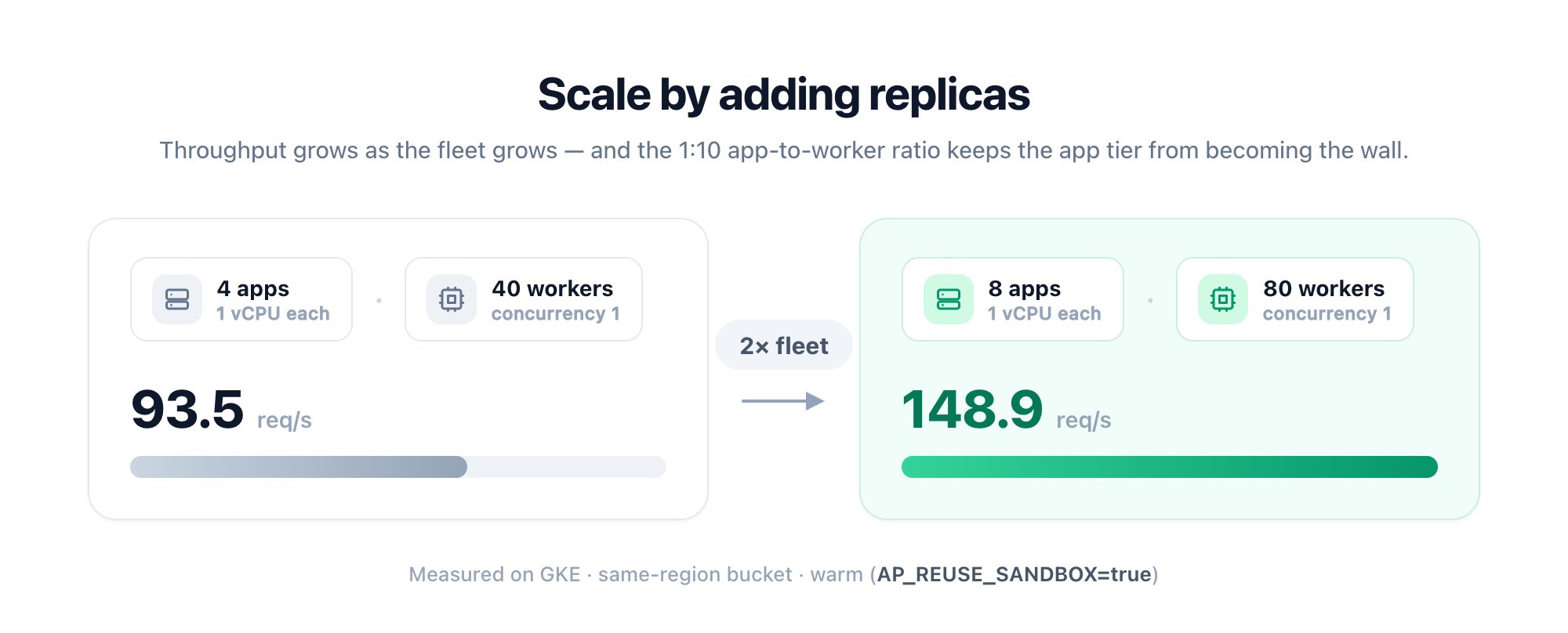
Limits
| Limit | Default | Env var |
|---|---|---|
| Flow run timeout | 600 s | AP_FLOW_TIMEOUT_SECONDS |
| Sync webhook response | 30 s | AP_WEBHOOK_TIMEOUT_SECONDS |
| Max webhook payload | 25 MB | AP_MAX_WEBHOOK_PAYLOAD_SIZE_MB |
| Step file size | 25 MB | AP_MAX_FILE_SIZE_MB |
| Flow run log size | 50 MB | AP_MAX_FLOW_RUN_LOG_SIZE_MB |
Need to reserve dedicated capacity for specific tenants? See Worker Groups.
Migrating from an earlier setup
Upgrading breaks nothing: the defaultAP_WORKER_CONCURRENCY=5 keeps each container running five flows at once. Reshaping to one flow per worker is opt-in, at the same total capacity. Keep total slots constant: slots = containers × concurrency.
| Before | After | |
|---|---|---|
| Per worker | ~2.5 vCPU / 5 GB, concurrency 5 | 0.5 vCPU / 1 GB, concurrency 1 |
| For 50 slots | 10 workers | 50 workers |
Apply the recommended config
AP_EXECUTION_MODE=SANDBOX_PROCESS; code-only mode is rejected for grouped workers.Co-locate S3
Drop dead vars
Remove
AP_PRE_WARM_CACHE; it no longer does anything (0.86.0).Not ready to reshape? Leave concurrency at 5 and size each container ~5× (≈5 GB).